Architectures of a Modern Data Platform
(Cross-posted from BigData Boutique Blog)This post is part of Architectures of a Modern Data Platform series.
We live in an era of data. Data is in every organization’s strategy, every engineer’s job description, and every CIO’s dreams (or nightmares). Day in, day out, more data collectors and more data generators are being built. The collectors are observability tools and data platforms, and the generators are users of applications and websites, IoT devices and sensors, and diverse levels of infrastructure.
This presents a challenge. The data itself presents untold opportunities and insights, but organizations consuming this data struggle to ingest, process, and query it in its vast volume. Data velocity is also an increasing problem for organizations, as they may not have the platforms or infrastructure in place to handle the data at the speed it’s generated or streamed.
Whilst many software solutions exist to address the challenges posed by such quantities of data, this in itself poses one of two challenges. One challenge is that the existing data platform uses legacy architectures or technologies, and is unable to scale, patch, and accommodate new requirements effectively. The other challenge is that organizations are embracing new technologies, but there is a pervasive lack of knowledge or experience. Some technologies are more common and have market dominance over others, but frequently organizations will use varying technologies and methodologies without clear direction and strategy.
As the tongue-in-cheek tweet above cleverly points out, the definition of big data is vague. However, the challenges caused by big data are well known and well documented. Perhaps the biggest challenge of all is the most obvious: how do you deal with it?
In this series of blog posts, we’re going to examine the challenges faced by organizations and the methodologies and architectures available to them to address big data problems. Today these problems for most organizations are storing and querying large volumes of data at rest, analyzing and deriving insights from data in real-time as it streams through the data pipelines, and all of that while maintaining economic efficiency.
Let’s look at how one can build a platform that helps deriving important insights from precious data, while keeping the cost-of-insight low so there is good return on investment to the business.
OLTP vs OLAP
A modern data platform is designed to accommodate OLAP systems, whilst those systems in turn partially rely upon OLTP systems. Before we dive into details, let’s examine the differences between the two and will explain exactly why you need both.
OLTP
The first part of a modern data platform is there to support online transaction processing (OLTP). This is normally the single source of truth for the system, where data entities are created, altered, and mutated. The most important characteristic of an OLTP system is its ACID guarantees. Since it’s supposed to maintain transactions, it is ought to provide Atomicity, Isolation and Consistency guarantees. The Durability requirement goes without saying, as this database is now your single source of truth.
Naturally, traditional SQL databases are often used as the OLTP part of the data platform, as they are fully ACID compliant and battle tested over decades of operation.
OLTP systems are used across multiple industries across the world to maintain a record of transaction data. Their role in a modern data platform is to store, record, and retrieve that data when queried. OLTP systems are fundamentally able to provide simple insights to end-users in a straightforward way. Because the data in data platforms is constantly evolving, mutable data (such as that stored in OLTP systems) needs to be reliable, such as with ACID guarantees.
Challenges with OLTP Systems
Whilst OLTP systems are perfect for serving as your single source of truth, they do have limitations. The biggest challenge with SQL databases which are frequently used for OLTP is schema management, ORMs and mismatch between objects and the normalized forms SQL databases are using. But those are well known and well documented challenges.
OLTP systems are designed to manage data mutations efficiently and consistently, and to safe-keep data. They will struggle when used as a serving layer or for analytics. Those usage-patterns will incur a large number of concurrent queries, and those queries will often require Join between tables and other costly read-time operations
Additionally, OLTP systems are not designed to handle “what if” queries or any type of complex decision-making.
Because of the above challenges, OLTP systems should always be used in conjunction with an OLAP system in a modern data platform. The OLAP system can support deep and costly analytics, usually be cheaper to maintain, and be used either as a serving layer in some occasions, or in addition to a separate serving layer.
Characteristics of OLAP Systems
Online Analytical Processing systems (OLAP) are used when you need to scale out analytics beyond basic queries, and when economically you can’t use OLTP systems for such computations. The OLAP system is normally a different, specialized type of database, that is built from the ground up to support efficient analytic-type queries.
OLAP systems are often used for performing business decisions, data mining, and carrying out complex calculations. Unlike OLTP systems, which act as a single source of truth, OLAP systems use historical data which is out of date. However, OLAP systems will often have additional data that isn’t present in OLTP systems.
Whilst OLTP systems are normally the data sources for OLAP systems, OLAP systems will often contain more detailed and enriched data fields than those found in OLTP systems. Updates to OLAP data are often pushed through in more lengthy batch operations, as opposed to real-time user-driven updates. The OLAP system usually stores a lot of information that isn’t typically stored on the OLTP layer - such as usage logs, events and a lot of other data that can be later used for behavioral analytics.
A common challenge with OLAP systems is to reduce the delta between them at OLTP systems, so that the data being analyzed is as close to the single source of truth as possible.
Queries are generally slower in OLAP systems for two reasons. First, OLAP systems will normally have far more data in them than OLTP systems. Second, OLAP systems will deal with far more complex queries. It also makes more economic sense to put fewer resources into an OLAP system to keep the cost of OLAP systems as low as possible, whilst maintaining a beneficial time to insight.
In this way, OLAP systems enable organizations to make data-driven decisions. If it weren’t for the ability to reduce cost of storage and compute, organizations may have opted to discard a lot of data that may have been useful later.
OLTP and OLAP Systems Together
To explain the synergy between OLTP and OLAP systems, take an eCommerce website as an example.
On the website, a cart will be maintained for each individual user as they progress through their shopping experience. This cart may have items from the eCommerce site’s catalog added or removed from it, and promotions may be applied. When an order is placed, both a record of the order and a record of its items will be created. This all occurs in an OLTP system.
The eCommerce organization’s OLAP system will maintain a copy of the data in the OLTP database but will contain various additional data fields that were enriched in a latent process while ingested to the OLAP platform. In the case of an eCommerce site, these will be fields that will assist the organization in deriving insights from the data. It’s the enrichment of that data, such as enhanced user profiles, customer spending history, and aggregations of orders, that drives efficient and actionable insights for organizations.
In addition to all past catalogs, user profiles and the full history of orders and order lines, the OLAP layer will often persist tables of immutable events of items added and removed from the cart, or user behavior on the website, and so on - which will allow to derive sophisticated insights such as alternate products, user reaction to promotions, product features and bugs, and so on.
When you hear people talking about either Data Warehouse or Data Lake solutions, in fact these are both OLAP systems.
Data Warehouse and Data Lake Architectures
The use of the term “data platform” is key. Today, the titles “Data Lake” and “Data Warehouse” are often used interchangeably and have slight differences in reality. Those differences are usually around maturity of the data and how well defined the schema used for it is. If done correctly, though, they tend to have similar architecture and both are describing OLAP systems. In this section, we are going to explore the common features of these solutions.
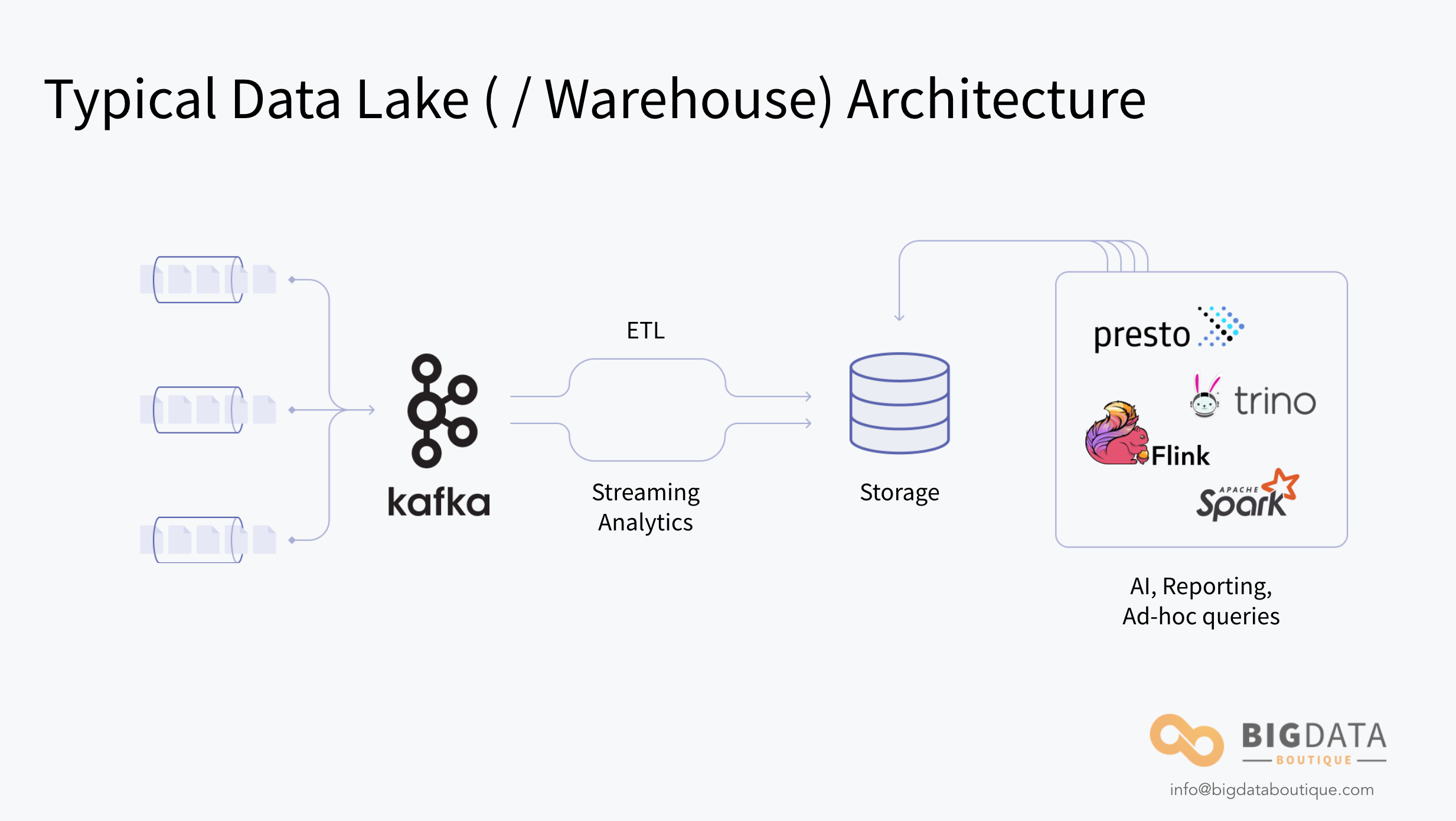
Data Ingest
At the start of a data platform is the data flowing in (depicted on the far left of the diagram above). The data will be flowing in from multiple sources (such as various OLTP databases, IoT devices and sensors, and many other sources) and subject to either real-time ingestions, micro-batch ingestion, or batch ingestion.
Real-time ingestion (or streaming ingestion) is a hot topic. As mentioned above, the smaller the delta between your data platform and the OLTP system, then the more accurate and useful the insights generated are. Whilst real-time ingestion data will never be truly ‘live’, it’s closer than batch ingestion.
Queuing
The backbone of a data platform is the queuing system. In the diagram, we’ve depicted Kafka acting as the queuing system and message broker, but it could be a variety of tools such as AWS Kinesis, Google PubSub, Apache Pulsar, or myriad others.
The queuing technology acts as a message broker between the ingested data and the ETL/ELT engines. The broker buffers data between the two stages, preventing the rest of the pipeline from being overwhelmed if there is a surge of data or an unexpected volume ingested. This is more of a risk with micro-batch and real-time ingestion as they are more prone to unforeseen floods of data being moved into the pipeline. In many cases, it also allows replaying events in case of error or when a new version is deployed.
ETL or ELT Engines
A vital part of a data platform after data has been ingested into the queue is the ETL or ELT engines. There are turnkey software products available such as Upsolver, but organizations with more varied data and greater big data challenges often build their own pipeline often based on open-source tools such as Airflow, Apache NiFi, and many many others. ETL and ELT engines are both intended for the same purpose. They take data and merge it, and the end product is left at rest in storage for the next stage of the process. How they achieve that end product varies.
Extract Transform Load (ETL) is the most common data processing model. An ETL process takes the buffered data from a wide variety of sources and regiments it into structured data. It then writes that converged data to a target, which is typically just storage optimized for querying.
Unlike ETL, ELT engines first move all the data onto the target storage and then carry out the transformative merging and converging, with an interactive approach where the result of each micro-transformation is also stored on the target storage. Whilst this is more costly in terms of storage resource, it means the whole process is auditable.
Storage
Storage is an important part of a data platform, particularly if you are running an ELT engine (see above). Selecting the correct storage is also important in terms of the jobs, queries, and analytics you plan on running on your data. It might be either object storage like AWS S3, Google Cloud Storage, or Azure Blob Storage, or solutions like Red Hat Ceph which are often used in data platforms in on-premises air-gapped data centers.
Stream Processing
Stream processing technologies have made huge progress in recent years. Use-cases that require low latency response, such as alerting, anomaly detection and so on can now be built and operated directly on the stream of incoming data and achieve great level of accuracy as well as great performance.
Traditional use-cases that previously required batch processing are now available for stream processing. This is made possible by tools like Flink and Kafka Streams, which computes data in real-time directly on the data streaming from the queue instead of waiting for it to move into storage first.
Usually executing computations and queries on optimized data on storage will be far more economical than running them on the stream, because of the computational resources required.
Batch Jobs and Query Engines
Once the data is at rest on storage, you’re able to run either batch jobs, machine learning jobs or ad-hoc queries against it for your analytics.
Batch jobs are normally analytics and data processing tasks run on a large volume of data at set intervals. In this more traditional approach, data is accumulated and then sent for processing en masse. This method of processing is normally more predictable in terms of compute resources required, hence more cost effective.
Whilst it has been around for a while, batch processing is still the first choice for use-cases such as generating reports, customer billing information, and order fulfillment. If you don’t require fresh and most recent up to date data, and can wait a bit for the response, then you might be better off running batch jobs.
This is usually true for Machine Learning and other types of clustering jobs, some ETL process, and so on. The usual go to technology here is Spark, and Flink can also be used for batch jobs just like it is being used for streaming analytics.
Some other technologies, namely Presto and Trino, were built to allow what we call “interactive queries” also on large volumes of data. That is why we refer to them here as query engines - their purpose is to enable the possibility of just querying the data, without running lengthy jobs. For that to work some things need to happen (storage optimization, proper cluster sizing, and few more).
Summary
There are a lot of factors to consider when choosing your future data platform. For every component we’ve discussed in this piece, there are a plethora of challenges. Data collection, running and monitoring ETL jobs, storage optimization, query performance, data cleanup, data quality - the list can be endless.
In the following posts in this series we will address the challenges we consider to be the biggest and most important. We will discuss the technologies that allow us to solve those challenges, and compare various approaches and solutions.
At BigData Boutique we provide consultancy on Big Data architectures and technologies, including hands-on development services. We also act as Architects-as-a-Service for organizations wishing to build or optimize their data platform. This blog and the following series is a summary of our experience in this field. Feel free to join us for the ride.