Running Elasticsearch on Kubernetes
Kubernetes is quickly becoming the de-facto standard for running systems in the cloud and on-premises, and in the last couple of years we at BigData Boutique have had to deploy and support quite a few Elasticsearch clusters on Kubernetes.
Now is probably a good time to reflect on this and have a high-level write up on the topic. How to run Elasticsearch on Kubernetes? should you even do that? and what should you watch out from?
But first, some important basics and concepts.
Kubernetes (Quick) Primer
Kubernetes is a container orchestration technology, which is just a fancy way of saying - it helps you manage and run your packaged applications. It basically looks like this:
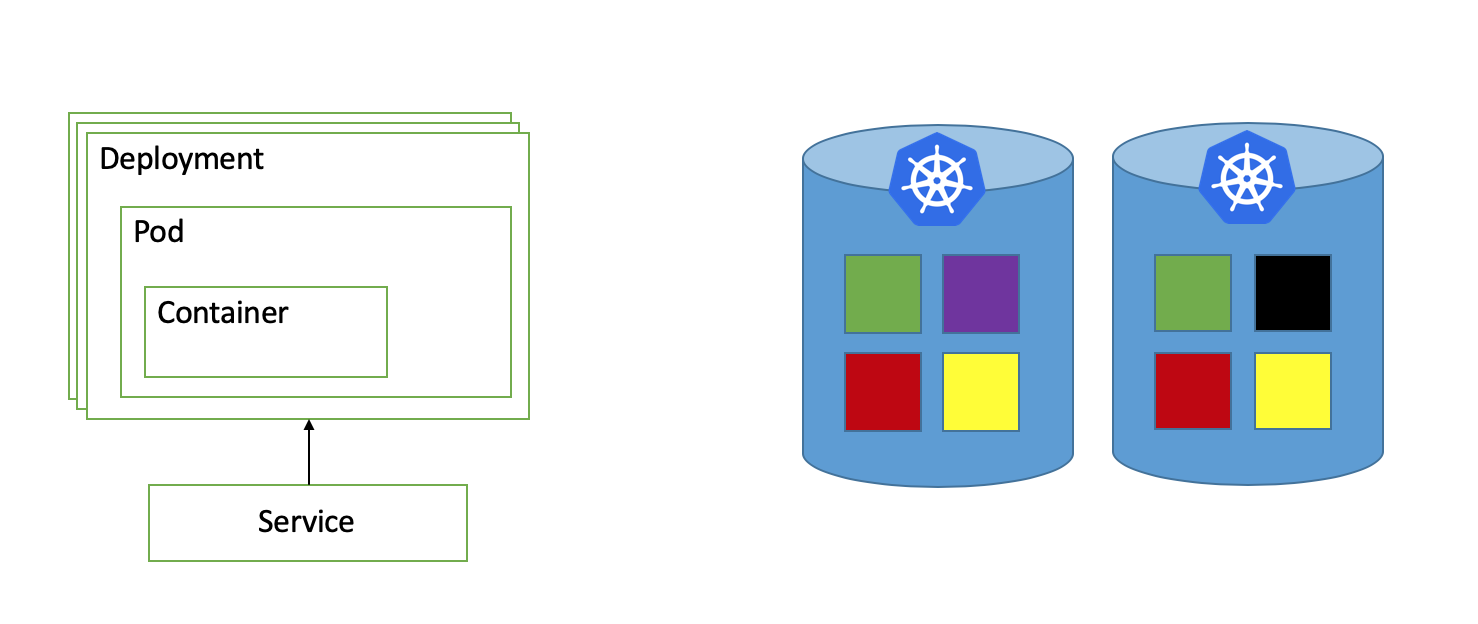
- Your application (e.g. blog software) is built and packaged within a Container.
- The containerized application is deployed to Kubernetes, and runs within a Pod.
- A Deployment is a Kubernetes concept for managing Pods and their properties, such as how many replicas of said Pod to run.
- A Service is used to expose Container ports to the world (if of LoadBalancer type), or at least to it's neighbor Deployments. In other words, a Service creates an IP address for the Container running under the hood.
- Kubernetes Services is what makes Pods in other deployments accessible to our Pod, e.g. our blog software can communicate with the database and email server via their respective Service, assuming of course they are running on Kubernetes.
- Kubernetes Nodes are running the Pods. The order of the pods on the nodes is by default arbitrary.
- You can use Affinity and Anti-Affinity rules to tell Kuberentes how to spread the running Pods on the nodes (e.g. All green Pods should never run on the same node in case it fails).
Kubernetes Deployments do not maintain any state whatsoever for their pods, as it is assumed the application running underneath is completely stateless. If you do want you application to maintain state and it's storage volume between restarts, like we do when we run a database or Elasticsearch in this case, you should use a StatefulSet which is a Deployment that can maintain state:
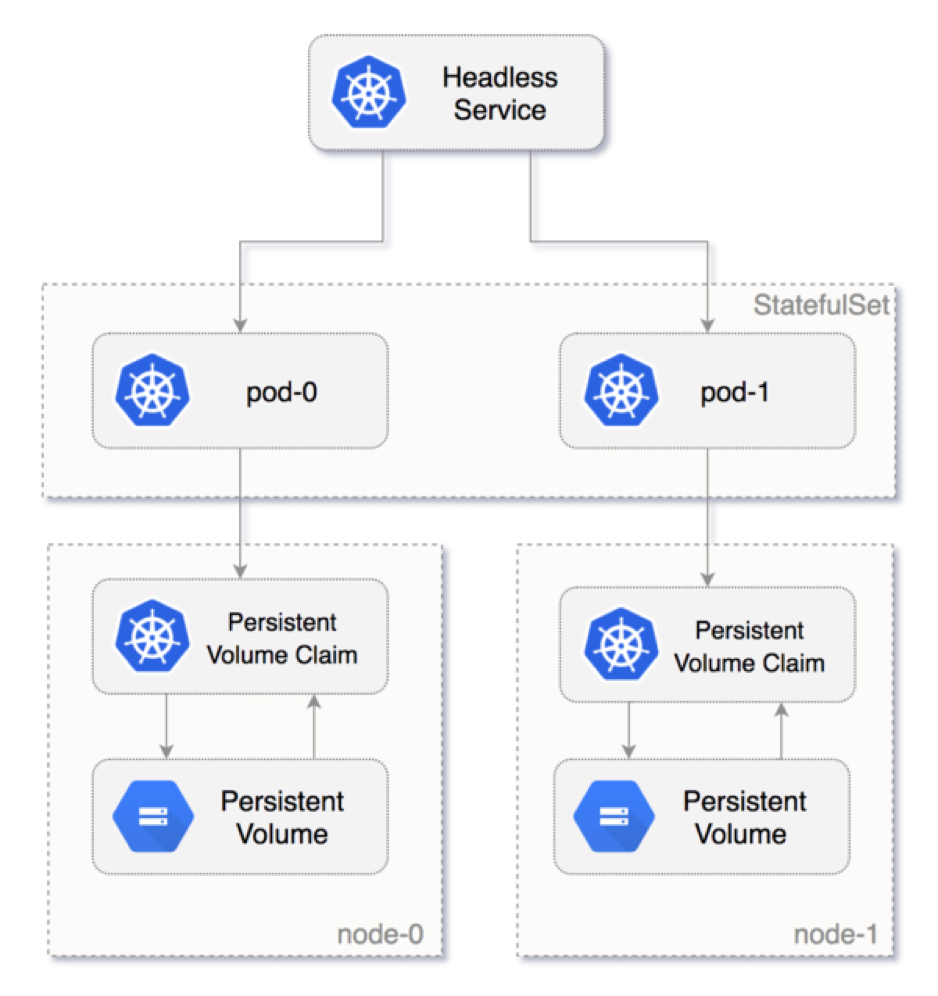
- A PersistentVolume (PV) is a Kubernetes abstraction for storage space on some volume provided by the underlying hardware. That can be AWS EBS drives, Google Cloud Disks, etc.
- A PersistentVolumeClaim (PVC) is a way for a Deployment, or StatefulSet, to request some storage space. The storage that has been allocated will survive Pod and Node restarts.
- StatefulSet is just another type of Deployment, but which is able to maintain Pod identities and Pods' volumes.
- A Headless Service is used for discovery by StatefulSet Pods.
Now that we have Kubernetes mostly explained, let's tackle the most important question of all:
Is Kubernetes a Good Choice for Elasticsearch?
Kubernetes was originally designed and built for running ephemeral workloads - meaning stateless applications and various jobs. Databases were never meant to run on Kubernetes and on containers in general. See here and here for some notable discussions on the topic.
StatefulSets which make stateful deployments work are a later addition, though they do work and work very well.
For me, I'd usually still avoid running any database or datastore on Kubernetes:
- The extra layer of abstraction has its performance penalties.
- Running databases and datastores on vanilla VMs let's you pick the right sizes without any resources waste. With Kuberenetes there's always some part of the VM running the Node that isn't being used.
- Resizing machines and disks is much easier when running on VMs.
- Running large clusters will be much harder to manage because of that added layer of abstraction (e.g. harder to decomission / restart several nodes while maintaining anti-affinity).
- As already stated, Kubernetes wasn't designed for stateful applications in the first place.
- Orchestration, automation, rolling updates etc for VM-based Elasticsearch clusters can be easily solved using Terraform, Pulumi, Ansible and a handful of other similar tools.
There are some cases where running Elasticsearch on Kubernetes can prove very useful indeed, and we might even recommend that:
- You are using Kubernetes for everything and not familiar with any other deployment method. In this case, reusing the existing infra is an important factor.
- In addition, you only need a very small to small cluster which likely doesn't justify managing yet another tool or deployment method. For a large cluster though, learning and using another tool or method will be worth saving the headache of managing it on Kuberenes.
- If your system needs to be deployed as SaaS on some public cloud but at the same time on-premises for your customers, using the same deployment and configuration.
For those cases when you do want to run Elasticsearch on Kubernetes, let's see how that's done.
Elasticsearch Cluster Topology
When working with the Elastic Stack, the part of it that needs special attention is Elasticsearch itself - that layer in the middle of the stack that stores the data and does all the magic. A typical Elasticsearch cluster will look something like this:
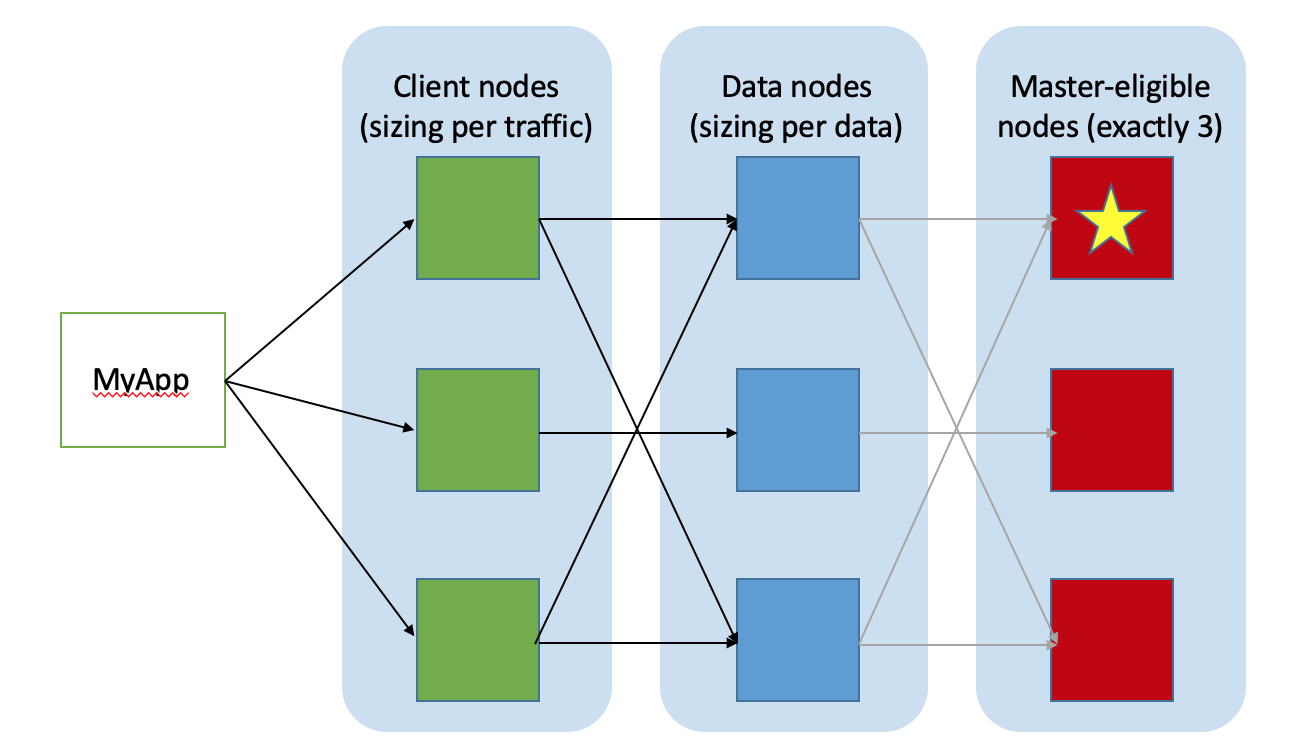
- At least 2 Data nodes, which will persist all data; they recieve queries and indexing requests, and do all of the heavy lifting.
- Exactly 3 Master-eligible nodes, which will manage the cluster metadata. Unlike what many think, Master nodes never deal with data operations, only cluster metadata operations. They never even come close to the data.
- Optionally, 2 or more Client nodes, also known as Coordinating nodes. These are the nodes that are exposed to consumers of the cluster data and serve as HTTP proxies. If they are not deployed, Data nodes will serve as coordinating nodes as well which is something we usually like to avoid on decent size clusters.
The cluster access point is then any of the coordinating nodes, or a load-balancer that can be put in front of them.
An Elasticsearch cluster topology running on Kubernetes will be very similar:
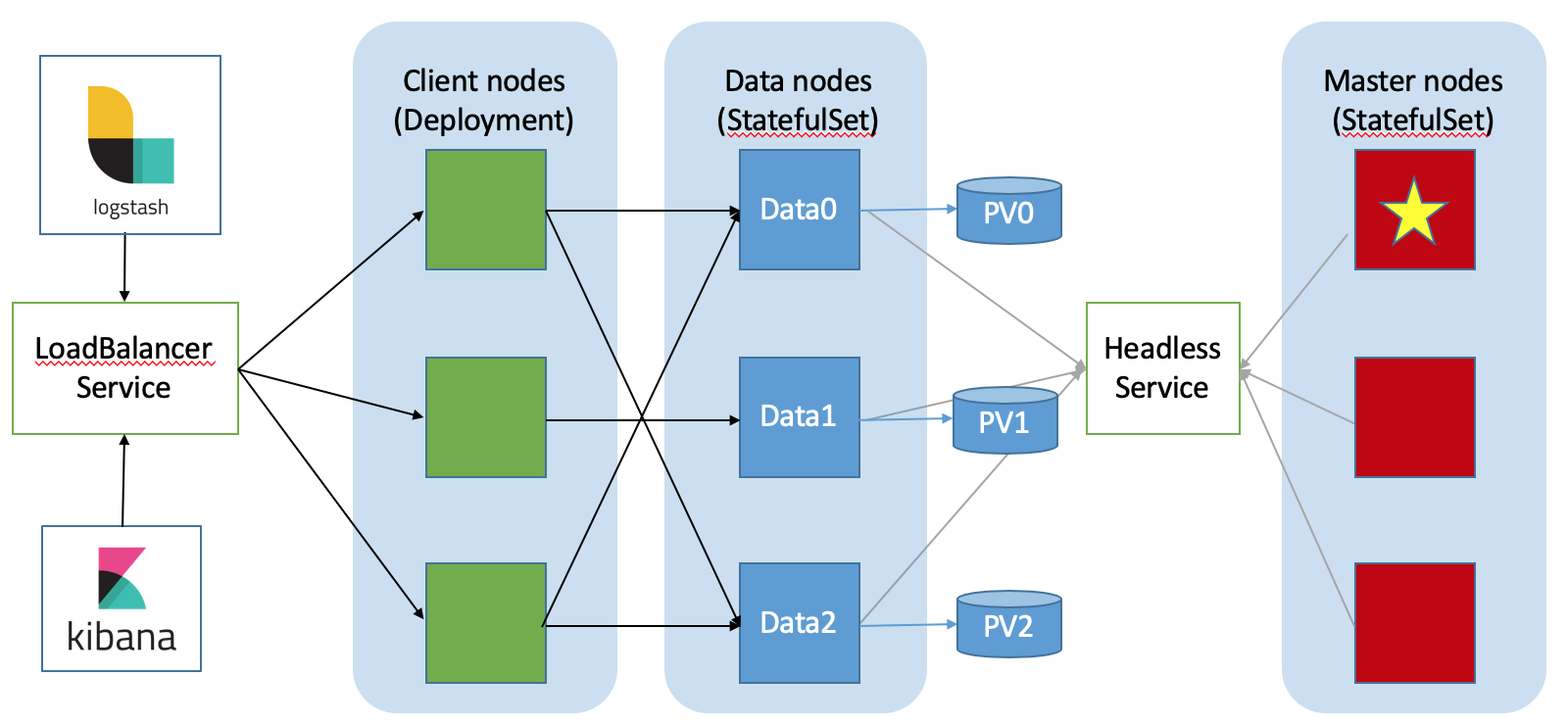
- The same layout of nodes; separate client nodes are still optional.
- Data nodes are deployed as StatefulSets with PV and PVCs. Therefore, they preserve their identity and storage also through restarts and crashes, which is the desired behavior.
- Master nodes can be deployed as either Deployments or StatefulSets. Deploying as StatefulSets will just make cluster recoveries faster.
- A headless service for each StatefulSet is created and used for inter-cluster discovery.
- Client nodes are completely stateless and can be deployed as a simple Kubernetes Deployment.
- A LoadBalancer Kubernetes Service is created to forward HTTP requests to the coordinating nodes.
- Your applications, as well as tools like Kibana, Logstash, Beats etc - should all be configured to talk to the LoadBalancer service. This is also where you should set up HTTPS security via Kubernetes Ingress or the like.
Deploying Elasticsearch on Kubernetes
There are currently two Helm Charts you can use to deploy Elasticsearch on Kubernetes. Both will create the topology as described above:
-
The Elasticsearch Helm Chart from the main charts repository: https://github.com/helm/charts/tree/master/stable/elasticsearch. It has a wide variety of configuration options and it's been around for quite a while.
-
The official Elastic Helm Chart, which is currently in Alpha status: https://github.com/elastic/helm-charts.
Alternatively, you can go hardcore and write the Kubernetes Yaml files yourself. It is not too difficult to pull off, just has a few gotchas (e.g. setting vm.max_map_count, securityContext.fsGroup: 1000, a correct readinessProbe, anti-affinity, etc).
In the next post, we will discuss some practical topics like handling Rolling Updates, Resource Allocation, Autoscaling, Creating and dealing with Availability Zones, Monitoring the cluster, and more.